
ビッグデータをリアルタイムで処理する、ストリームデータ処理ツールGUST(ガスト)のすべて 4-1

SUMMARY
- 現代は、企業が生み出すデータ量が1日あたり10テラバイトという情報“爆発”社会
- データを「ストックする」のではなく「取捨選択してフローする」ことが、ビッグデータを宝の山に変える
- ビッグデータ活用の鍵は、「すぐには使えない膨大なデータの処理」にある
独自の分散KVSテクノロジーを活用し「大量データを高速に処理する」認証基盤やIoT基盤などのソリューションを提供しているかもめエンジニアリングでは、2015年6月からストリームデータ処理ツールGUST(ガスト)の提供を開始しました。
ストリームデータ処理とは、すべてのデータをストレージにストックしてから処理していた従来の手法に代わり、データをリアルタイムに処理する基盤です。企業が保有するデータが日に日に膨れ上がるなか、注目を集めているテクノロジーです。
このシリーズではビッグデータをリアルタイムに処理するストリームデータ処理ツールGUSTについてご紹介します。
シリーズ1回目の今回は、情報“爆発”社会で求められるデータ処理のあり方について考察します。
企業が生み出すデータ量が1日あたり10テラバイトという情報“爆発”社会
現在、1分間でどのぐらいのデータが飛び交っているか、想像できますか?
たった60秒の間に10万ツィート、70万件のフェイスブックへの投稿、1億7000万のEメールが送信されている現代は、まさに情報“爆発”社会という様相を呈しています。
もはや1~10テラバイト程度であれば、中堅~大手企業の1日あたりのデータ量としてデフォルトと言われています。一節には、この世に散見するデータ量は、全世界の砂浜に敷き詰められた砂粒の数よりも多いとも言われているのです。
このような社会を背景に、企業におけるビッグデータの管理にさまざまな課題が生じています。
データは「ストックする」から「フローする」へ
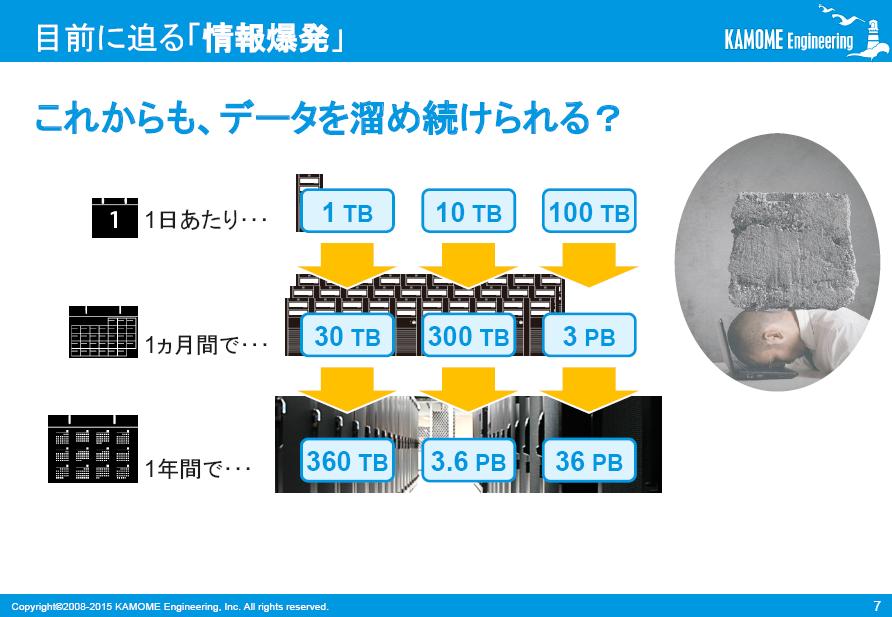
社内データが1日あたり1テラバイト蓄積されることを仮定すると、そのデータは、1ヶ月で30テラバイトとなり、1年間で360テラバイトにまで増殖します。つまり社内データを蓄え続けようとすれば、巨大なストレージが必要となってくるのです。
さらにストレージの問題だけでなく、データ量が増えることによって、データ処理に対する課題も膨らみます。
たとえば、通信業からはこのような声が届いています。
「1システムだけで、ログが1日に40テラバイト蓄積される。このペースで行けば、近いうちにデータの有効活用ができなくなる」
またWeb広告業では、このような課題に直面しています。
「行動ターゲティング広告に使用するデータが、1時間あたり4テラバイト来る。これを1時間以内に解析して広告表示しなければならないが、現在利用しているバッチ処理では処理に数時間から1日かかる。リアルタイム処理ができないため、タイムリーな広告表示ができない」
このほかにも業種に関わらず次のような声があがっています。
「データ量が膨らみすぎてストレージが足りないが、新規ストレージ設備投資には費用がかかりすぎる」
「データ量が大きすぎて、Hadoopなどの分散処理技術を用いても分析できない。分析できたとしても時間がかかりすぎる」
「ビッグデータをモニタリングし、特定の条件のデータを抽出したいが、データ量が大きすぎるため、不正アクセスの検知などがリアルタイムに処理できない」
このほかにも、たとえば1分1秒単位での判断が要求される経営データなどはリアルタイムで処理がなされないと、企業そのものの命運を左右する可能性さえあるのです。
こういった課題を解決するためには、データ処理についての発想の転換が急務となります。
すなわちデータを「ストックする」のではなく、「取捨選択してフローする」ことへの転換です。
ストリームデータ処理最新情報
「データを取捨選択する」ための4つのポイント
「データを取捨選択する」ポイントは、次のようなものです。
●データ内に、解析に不要なデータが混じっていないか?
→不要なデータが混ざっていると、クレンジングの煩雑な手間がかかります。
●ストレージの容量が足りているか?
→データ処理のために新たな設備投資が必要になります。
●データ量が多すぎて分析できない状態に陥っていないか?
→分析のために新たなデータマートを作成する必要があります。
●他のデータと突き合わせる必要があるか?
→もし突き合わせデータが増えれば、膨大なデータを前に人海戦術となります。
企業にとってビッグデータは「宝の山」と形容されます。
しかし膨大な宝の山から必要な情報をすぐに取り出すことができなければ、それは保有していないことと同義です。
この矛盾を解消し、ビッグデータを活用する鍵は「すぐには使えない膨大なデータの処理」にあるのです。
ストリームデータ処理ツール「GUST」についてもっと知りたい方は、こちらへ







